Upowszechniło się generowanie komentarzy do filmików na YT za pomocą syntezatorów mowy. Nie ma co się jednak dziwić, jeśli sprowadza się to do założenia konta, dostosowania skryptu, wybrania głosu i wpisania tekstu do przeczytania. Poniżej rozwiązanie oparte na
W macOS trzeba zainstalować pythona, np tak:
brew install python
Potem instalacja PIPa
curl https://bootstrap.pypa.io/get-pip.py -o get-pip.py
python3 get-pip.py
Założenie konta na https://elevenlabs.io/speech-synthesis i wyciągnięcie swojego klucza API Key
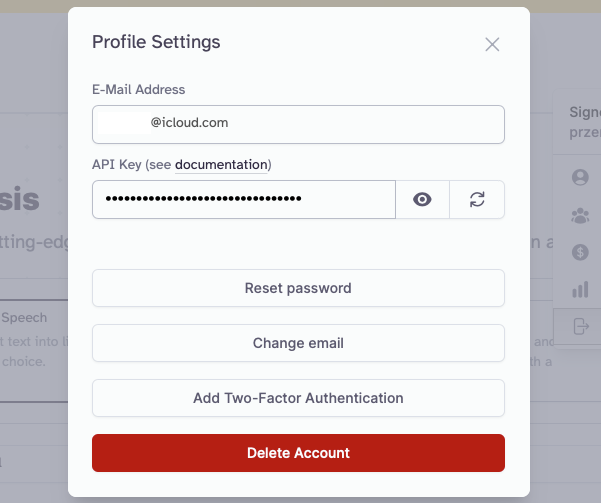
I wstawienie do skryptu pythonowego speak.py w miejsce xi-api-key
import requests
CHUNK_SIZE = 1024
url = "https://api.elevenlabs.io/v1/text-to-speech/21m00Tcm4TlvDq8ikWAM"
headers = {
"Accept": "audio/mpeg",
"Content-Type": "application/json",
"xi-api-key": "xxxxxxxxxxxxxxxxxxxxxx"
}
data = {
"text": "O Jejku, nie wiem. Byle jakiś, bo teraz nie wymyślę niczego! ",
"model_id": "eleven_multilingual_v2",
"voice_settings": {
"stability": 0.5,
"similarity_boost": 0.5
}
}
response = requests.post(url, json=data, headers=headers)
with open('output.mp3', 'wb') as f:
for chunk in response.iter_content(chunk_size=CHUNK_SIZE):
if chunk:
f.write(chunk)Wywołanie tego poprzez python3 speak.py generuje lokalnie output.mp3. Użycie modelu eleven_multilingual_v2 zwalnia z jawnego deklarowania języka - sam rozpozn, że chodzi o język polski.
Output
0:00
/3.709387755102041